一、数据库的好处
- 持久化数据到本地
- 可以实现结构化查询,方便管理
二、数据库相关概念
- 数据库 DB(DataBase):保存一组有组织的数据的容器。
- 数据库管理系统 DBMS(DataBase Management System):又称为数据库软件,用于管理DB中的数据,比如 MySQL、Oracle、SQL Server…
- 结构化查询语言 SQL(Structured Query Language):SQL 用来和数据库打交道,完成和数据库的通信。
- 表(table):用来存储特定类型的数据,具有行和列两种属性。数据存储在表中,表再放在库中。一个数据库可以有多个表,但表名不能重复。
- 列(column):又称为字段, 每一列存储着相同类型的数据。
- 行(row):表中的一个记录,每一行记录着一组完整的信息。
- 主键(primary key):主键是一列,通过主键可以唯一区分表中的每一行,如果一列为主键,那么这一列中的数据不能有重复。比如学生的学号可以唯一标识一个学生的信息,那么其可以作为主键,而学生的姓名由于存在同名的可能,就不能作为主键。
三、MySQL 简介
1. MySQL 使用
① MySQL 服务的启动和停止
- 方式一:计算机——右击管理——服务
- 方式二:通过管理员身份运行 cmd,输入命令:
net start 服务名(启动服务)net stop 服务名(停止服务)
② MySQL 服务的登录和退出
- 登录:mysql 【-h主机名 -P端口号 】-u用户名 -p密码
- 退出:exit 或 ctrl+C
2. MySQL 的语法规范
- 不区分大小写,但为了提高可读性,关键字一般大写,其他小写;
- 每条命令最好用分号结尾;
- 每条命令根据需要,可以进行缩进或换行以便提高可读性;
- 注释
- 单行注释:# 注释文字
- 单行注释:– 注释文字
- 多行注释:/* 注释文字 */
3. SQL的语言分类
DQL(Data Query Language):数据查询语言,selectDML(Data Manipulate Language):数据操作语言,insert 、update、deleteDDL(Data Define Languge):数据定义语言,create、drop、alterDCL(Data Control Language):数据控制语言,commit、rollback
四、SQL 语言
1. DDL 语言的学习
① 库和表的管理
库的管理:
创建库
1
create database 【if not exists】库名;
删除库
1
drop database 【if exists】库名;
查看当前所有的数据库
1
show databases;
查看当前数据库
1
select datebase()
使用当前数据库
1
user 数据库名
表的管理:
创建表 create table
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18# 语法
create table 【if not exists】 表名(
字段名 字段类型 【约束】,
字段名 字段类型 【约束】,
...
字段名 字段类型 【约束】
);
# 示例
# 创建一个学生表,包含学号、姓名、班级、性别、分数和电话号码
create table students(
id int,
name varchar(10),
grade int,
gender char(1),
score int,
phone varchar(20)
);修改表 alter table
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23# 语法
1).添加列
alter table 表名 add column 列名 类型 【first|after 字段名】;
2).修改列的类型或约束
alter table 表名 modify column 列名 新类型 【新约束】;
3).修改列名
alter table 表名 change column 旧列名 新列名 类型;
4).删除列
alter table 表名 drop column 列名;
5).修改表名(重命名表)
alter table 表名 rename 【to】 新表名;
# 示例
# 在学生表中添加一列用于显示email(邮箱)
alter table students add column email varchar(20);
# 将学生表中的电话号码类型改为int
alter table students modify column phone int;
# 将学生表中的name列名称改为stu_name
alter table students change column name stu_name varchar(20);
# 将学生表中的email列删除
alter table students drop column email;
# 将学生表名改为stu_tables
alter table students rename to stu_tables;删除表 drop table
1
2# 语法
drop table【if exists】 表名;复制表
1
2
3
4
5
6
7
8# 语法
# 1)、复制表的结构
create table 表名 like 旧表;
# 2)、复制表的结构+数据
create table 表名
select 查询列表
from 旧表
【where 筛选】;查看表
1
2
3
4
5
6
7# 语法
# 1)、查看当前库的所有表
show tables;
# 2)、查看其它库的所有表
show tables from 库名;
# 3)、查看表结构
desc 表名
② 常见类型
数值型
tinyint、smallint、mediumint、int、bigint、double(M,D)、float(M,D)、decimal(M,D)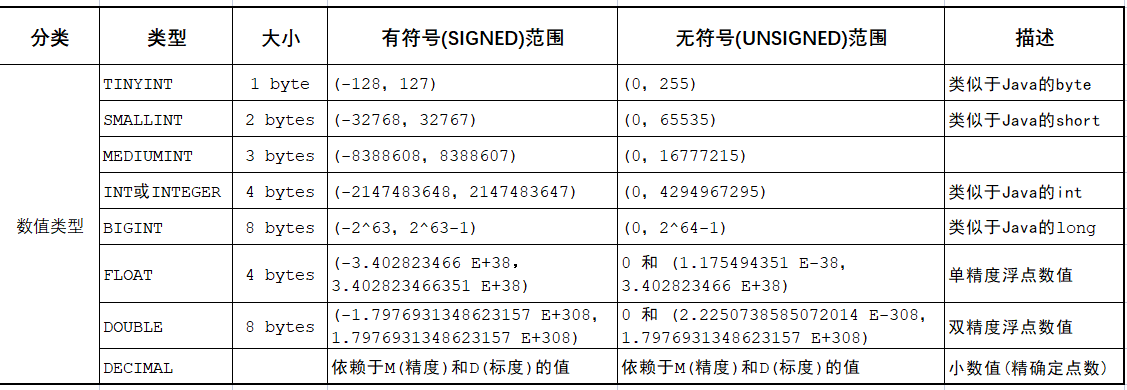
整数
- 都可以设置无符号和有符号,默认有符号,通过 unsigned 设置无符号,有符号和无符号占用相同的磁盘空间,并具有相同的性能。
- 如果超出了范围,会报 out of range 异常,并插入临界值;
- 长度可以不指定,默认会有一个长度,长度代表显示的最大宽度,如果不够则左边用 0 填充, 但需要搭配 zerofill,并且默认变无符号整型。注意指定的长度只是用来显示字符的个数。对于存储和计算来说,INT(1) 和 INT(20) 是相同的 。
- 一般情况下,应该尽量使用可以正确存储数据的最小数据类型,如只需存 0~200,tinyint unsigned 更好。
小数
- M 代表整数部位 + 小数部位的个数,D 代表小数部位
- 如果超出范围,则报 out or range 异常,并且插入临界值
- M 和 D 都可以省略,但对于定点数,M 默认为 10,D 默认为 0
- 如果精度要求较高,则优先考虑使用定点数
- float 占用 4 字节,double 占用 8 字节
字符型:
char、varchar、binary、varbinary、enum、set、text、blob
- varchar 用于存储可变长字符串,它仅使用必要的空间。需要额外适用 1~2 个字节记录字符串的长度,如果列的最大长度小于或等于 255,用 1 个字节记录长度,否则用 2 个字节记录长度。
- char 用于存储定长字符串,适合存储很短的字符串或所有值都接近同一个长度。比如适合存储密码的 MD5值,对于经常变更的数据,char 比 varchar 更好,因为定长的 char 不容易产生碎片,且在存储空间上更有效率(因为 varchar 要额外记录长度)。
- Blog 和 Text 用于存储很大的数据,分别采取二进制和字符方式存储。
日期型:
year年、date日期、time时间、datetime日期+时间、timestamp日期+时间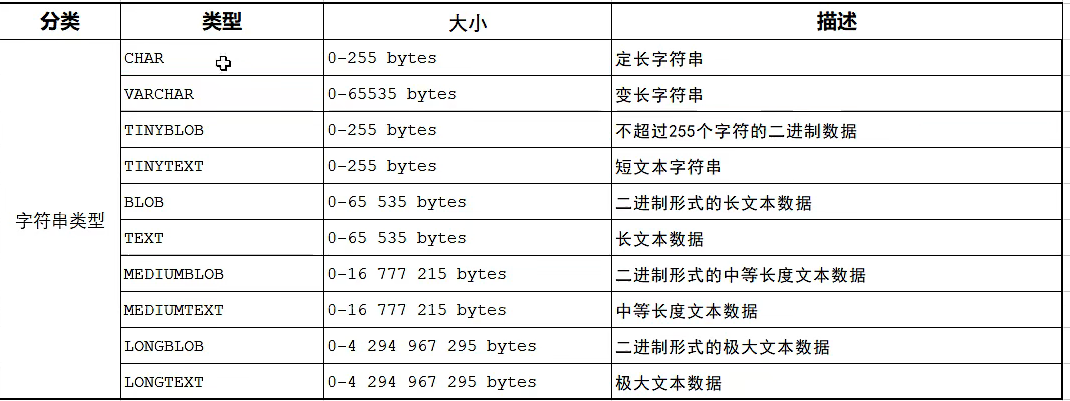
- timestamp 只占用 datetime 一半的存储空间,但允许的时间范围更小。
③ 常见约束
定义
一种限制,用于限制表中的数据,为了保证表中的数据的准确和可靠性
常见约束
NOT NULL:非空,表示该字段的值必填。通常情况下,最好指定列为 NOT NULL,除非真的需要存储 NULL 值,如果查询中包含可为 NULL 的列,对 MySQL 来说更难优化,因为可为 NULL 的列使得索引、索引统计和值比较都更复杂。可为 NULL 的列会使用更多的存储空间。UNIQUE:唯一,表示该字段的值不可重复DEFAULT:默认,表示该字段的值如果不插入会有默认值CHECK:检查,mysql 8.0.16 版本后才支持PRIMARY KEY:主键,表示该字段的值不可重复并且非空 unique+not nullFOREIGN KEY:外键,表示该字段的值引用了另外的表的字段(弊大于利,有利于数据一致性,但会导致更新一张表还得去查其外键表,慢,而且复杂不利于开发)
主键与唯一的区别
- 一个表至多有一个主键,但可以有多个唯一;
- 主键不允许为空,唯一可以为空。
添加约束有两种时机
创建表时添加约束
1
2
3
4
5
6
7
8
9
10
11
12
13
14# 语法
CREATE TABLE 表名(
字段名 字段类型 列级约束,
字段名 字段类型,
表级约束
)
# 示例:
create table 表名(
字段名 字段类型 not null, # 非空
字段名 字段类型 primary key, # 主键
字段名 字段类型 unique, # 唯一
字段名 字段类型 default 值, # 默认
constraint 约束名 foreign key(字段名) references 主表(被引用列)
)修改表时添加或删除约束
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25# 1、非空
# 添加非空
alter table 表名 modify column 字段名 字段类型 not null;
# 删除非空
alter table 表名 modify column 字段名 字段类型 ;
# 2、默认
# 添加默认
alter table 表名 modify column 字段名 字段类型 default 值;
# 删除默认
alter table 表名 modify column 字段名 字段类型 ;
# 3、主键
# 添加主键
alter table 表名 add【 constraint 约束名】 primary key(字段名);
# 删除主键
alter table 表名 drop primary key;
# 4、唯一
# 添加唯一
alter table 表名 add【 constraint 约束名】 unique(字段名);
# 删除唯一
alter table 表名 drop index 索引名;
# 5、外键
# 添加外键
alter table 表名 add【 constraint 约束名】 foreign key(字段名) references 主表(被引用列);
# 删除外键
alter table 表名 drop foreign key 约束名;注意:
表级约束语法:在各个字段的最下面【constraint 约束名】 约束类型(字段名)
特殊:【constraint 约束名】 foreign key(字段名) references 主表(被引用列)
表级约束的 constraint 约束名可省略,如可以直接 primary key(id)
列级约束和表级约束的区别
列级约束除了外键都支持,而且不可以起约束名;表级约束除了非空和默认均支持,并且除了主键均可起约束名称;
列级约束可以在一个字段上追加多个,中间用空格隔开,没有顺序要求。
自增长列
特点:
- 不用手动插入值,可以自动提供序列值,默认从 1 开始,步长为 1,可以通过下面语句改变步长:
set auto_increment_increment=值; - 一个表至多有一个自增长列
- 自增长列只能支持数值型
- 自增长列必须为一个 key
语法:
1
2
3
4
5
6
7
8# 一、创建表时设置自增长列
create table 表(
字段名 字段类型 约束 auto_increment
)
# 二、修改表时设置自增长列
alter table 表 modify column 字段名 字段类型 约束 auto_increment
# 三、删除自增长列
alter table 表 modify column 字段名 字段类型 约束- 不用手动插入值,可以自动提供序列值,默认从 1 开始,步长为 1,可以通过下面语句改变步长:
2. DQL语言的学习【重点】
编写顺序与执行顺序:

① 基础查询
语法:
1 | select 查询列表 |
特点:
- 通过 select 查询完的结果 ,是一个虚拟的表格,不是真实存在
- 要查询的东西可以是常量值、可以是表达式、可以是字段、可以是函数
- 可以没有 from 语句
- 先执行 from 语句,再执行 select 查询
示例:
1 | # 查询单个字段 |
② 条件查询
条件查询:根据条件过滤原始表的数据,查询到想要的数据
语法:
1 | select 查询列表 |
特点:
先执行from语句,在执行where语句,最后执行select语句
分类:
条件表达式
>、< 、>=、 <=、 =、 !=、 <>、 <=>,安全等于 <=> 可以判断 null 值,而 = 不能判断 null 值between 值1 and 值2,筛选所需要的值在值1和值2之间,等同于 >=值1 and <=值2is null /is not null,用于判断 null 值(也只能判断 null 值)in / not in,in是指包含,后面接(值1,值2…),相当于多个 or,但效率更高示例
1
2
3
4# 筛选学生表中:姓名为张三的所有信息。
select *
from students
where name='张三';
逻辑表达式
and(&&),两个条件如果同时成立,结果为 true,否则为 falseor(||),两个条件只要有一个成立,结果为true,否则为falsenot(!),如果条件成立,则not后为false,否则为true示例
1
2
3
4# 示例:筛选学生表中:分数在60和70之间的学生全部信息。
select *
from students
where score>=60 and scord<=70;
模糊查询
like, 通常搭配通配符使用,%任意多个字符,_任意单个字符(%不能表示null)示例
1
2
3
4# 示例:筛选学生表中:姓名第二个字为伟的学生全部信息
select *
from students
where name like '_伟%';
③ 排序查询
排序查询:对查询的结果按某一字段进行排序。
语法:
1 | select 查询列表 |
特点:
- 可以没有 where 筛选语句
- asc 值升序,desc 指降序,如果不写默认为升序
- 排序列表支持单个字段、多个字段、函数、表达式、别名
- order by 的位置一般放在查询语句的最后(除 limit 语句之外)
- 先执行 from 语句,再执行 where 语句,然后执行 select,最后执行 order by 排序
示例:
1 | # 查询学生表中:所有姓张的学生全部信息,并按照考试成绩进行降序排列 |
④ 常见函数
1) 单行函数
concat:将多个字段/字符进行拼接。
1
2
3
4# 语法:concat(字段/字符1,字段/字符2,...,字段/字符n)
# 示例:查询学生表中:所有学生的姓名和成绩,并显示为一列,格式示范:张三(98分)
select concat(name,'(',score,'分)') as 姓名(分数)
from students;ifnull:判断某字段或表达式是否为null,如果为null 返回指定的值,否则返回原本的值
1
2
3
4# 语法:ifnull(字段/表达式,指定值)
# 示例:查询学生表中:所有学生的姓名和成绩,并将原来成绩为null(没参加考试)的同学成绩改为0分
select name,ifnull(score,0)
from students;isnull:判断某字段或表达式是否为null,如果是,则返回1,否则返回0
1
2
3
4# 语法:ifnull(字段/表达式)
# 示例:查询学生表中:所有学生的姓名以及是否缺考,如果缺考记为1,否则记为0
select name,ifnull(score)
from students;substr:截取子串
1
2
3
4# 语法:substr(字段/字符,初始索引,截取字符长度)
# 注意:字符串索引从1开始,而不是从0开始,如果截取字符长度省略,则截取到最后。
# 示例:截取一个字符串的前三个字母
select substr('zhang',1,3); #查询结果为zhalength :获取字节个数
1
2
3
4# 语法:length(字段/字符)
# 注意:获取的是字节个数,而不是字符个数,在utf8编码中,1个汉字为3个字节,1个字母为1个字节。
# 示例:
select length('123张'); #查询结果为6instr:返回子串第一次出现的索引
1
2
3
4
5# 语法:instr(字段/字符,子串)
# 注意:如果字串不在原字符中,则返回0
# 示例:
select instr('123六六456','六六'); #查询结果为4
select instr('123六六456','六六六'); #查询结果为0round:四舍五入
1
2
3
4# 语法:round(数字,保留小数位数)
# 注意:保留小数位数可以不写,那么默认四舍五入为整数。
# 示例:
select round(4.76,1); #查询结果为4.8truncate:截断
1
2
3
4# 语法:truncate(数字,保留小数位数)
# 注意:保留小数位数可以不写,那么默认截断为整数。截断不是四舍五入,而是均舍掉,4.1、4.9截断均为4。
# 示例:
select truncate(4.76,1); #查询结果为4.7rand:0-1 之间随机数
1
2
3# 语法:rande()
# 示例:
select rand(); #返回一个范围在0-1之间的随机值floor:向下取整
1
2
3
4# 语法:floor(数字)
# 注意:返回一个不大于括号中值的最大整数。
# 示例:
select floor(4.7); #查询结果为4ceil:向上取整
1
2
3
4# 语法:floor(数字)
# 注意:返回一个不小于括号中值的最大整数。
# 示例:
select ceil(4.7); #查询结果为5mod:取余
1
2
3
4# 语法:mod(数1,数2);
# 注意:返回结果为数1除以数2所得的余数。
# 示例:
SELECT MOD(10,3); #查询结果为1now:当前系统日期+时间
1
2
3# 语法:now();
# 示例:
SELECT now(); #查询结果为:2020-07-08 16:43:35curdate:当前系统日期
1
2
3# 语法:curdate();
# 示例:
SELECT curdate(); #查询结果为:2020-07-08curtime:当前系统时间
1
2
3# 语法:curtime();
# 示例:
SELECT curtime(); #查询结果为:16:45:28str_to_date:将字符转换成日期
1
2
3
4# 语法:str_to_date(字符,日期格式);
# 注意:%Y是年,%m是月,%d是日,%H是小时,%i是分,%s是秒
# 示例:
select str_to_date('2020-7-8','%Y-%m-%d'); #查询结果为:2020-07-08date_format:将日期转换成字符
1
2
3
4# 语法:date_format(日期,日期格式);
# 注意:%Y是年,%m是月,%d是日,%H是小时,%i是分,%s是秒
# 示例:
select date_format('2020-7-8','今天是%Y年%m月%d日')); #查询结果为:今天是2020年07月08日其他日期函数
1
2
3
4
5
6
7select date(now()); #返回日期,结果为:2020-07-08
select year(now()); #返回年,结果为:2020
select month(now()); #返回月
select day(now()); #返回日
select minute(now()); #返回分钟
select second(now()); #返回秒
select datediff('2020-08-08','2020-07-08'):# 返回两个日期相差的天数,结果为:31
2)分组函数/聚集函数
聚集函数:作用于一组函数,最后返回一个值
分类:sum() 求和、min() 最小值、max() 最大值、avg() 平均值、count() 计数
特点:
- *以上五个分组函数都忽略 null 值,除了count()**(注意:count(具体字段)会忽略null值);
- sum 和 avg 一般用于处理数值型,max、min、count可以处理任何数据类型;
- 都可以搭配 distinct 使用,用于统计去重后的结果。
示例:
1 | # 查询学生表中,学生成绩的总和、最小值、最大值、平均成绩以及学生总人数 |
⑤ 分组查询
分组查询:将查询结果按照1个或多个字段进行分组,字段值相同的为一组。
语法:
1 | select 查询的字段,分组函数 |
特点:
- where 语句、having 语句和 order by 语句可以没有;
- 可以按单个字段分组,也可以按多个字段分组,字段之间用逗号隔开;
- 和分组函数一同查询的字段最好是分组后的字段,其他字段没有意义;
- 分组筛选
- where 在分组前对原始表进行筛选,位于group by的前面,不能对聚合函数进行判断
- havng 在分组后对分组后的结果集进行筛选,位于group by的后面,可以对聚合函数进行判断
- having 后可以支持别名;
- 先执行 from,再执行 where,然后执行 group by,having,接着执行 select,最后执行 order by。
示例:
1 | # 查询学生表中,每个班级的平均分数,并根据此进行降序排列 |
⑥ 连接查询
连接查询:所要查询的内容在多个表中,对多个表进行连接后查询
笛卡尔乘积:如果连接条件省略或无效则会出现。检索出的行数目等于第一个表中的行数乘以第二个表的行数。
解决办法:添加上连接条件
SQL92语法(了解):支持内连接(等值连接、非等值连接、自连接)
等值连接
1
2
3
4
5
6
7select 查询列表
from 表1 别名,表2 别名
where 表1.key=表2.key
【and 筛选条件】
【group by 分组字段】
【having 分组后的筛选】
【order by 排序字段】- 一般为表起别名;
- 多表的顺序可以调换;;
- n表连接至少需要n-1个连接条件;
- 等值连接的结果是多表的交集部分。
非等值连接
1
2
3
4
5
6
7select 查询列表
from 表1 别名,表2 别名
where 非等值的连接条件
【and 筛选条件】
【group by 分组字段】
【having 分组后的筛选】
【order by 排序字段】自连接
1
2
3
4
5
6
7select 查询列表
from 表 别名1,表 别名2
where 等值的连接条件
【and 筛选条件】
【group by 分组字段】
【having 分组后的筛选】
【order by 排序字段】
SQL99语法(重点):支持内连接(等值连接、非等值连接、自连接)、外连接(左外、右外、全外)和交叉连接。
内连接
语法:
1
2
3
4
5
6
7
8
9select 字段,...
from 表1
【inner】 join 表2 on 连接条件
【inner】 join 表3 on 连接条件
...
【where 筛选条件】
【group by 分组字段】
【having 分组后的筛选条件】
【order by 排序的字段或表达式】特点:
- ① 一般为表起别名;
- ② 多表的顺序可以调换;
- ③ n 表连接至少需要 n-1 个连接条件;
- ④ 内连接的结果是多表的交集部分;
- ⑤ inner 关键字可以省略;
- ⑥ 先执行 from,再执行 join on,接着 where,之后 group by having,然后 select,最后 order by
外连接
语法:
1
2
3
4
5
6
7
8
9select 字段,...
from 表1
left/right/full 【outer】 join 表2 on 连接条件
left/right/full 【outer】 join 表3 on 连接条件
...
【where 筛选条件】
【group by 分组字段】
【having 分组后的筛选条件】
【order by 排序的字段或表达式】特点:
- ① 查询的结果=主表中所有的行,如果从表和它匹配的将显示匹配行,如果从表没有匹配的则显示null;
- ② 多表的顺序很重要,left join 左边的是主表,right join 右边的就是主表,full join 两边都是主表;
- ③ outer 关键字可以省略
交叉连接(不常用,关键字为 cross join)
⑦ 子查询
子查询:一条查询语句中又嵌套了另一条完整的select语句,其中被嵌套的select语句,称为子查询或内查询
主查询:在外面的查询语句,称为主查询或外查询
特点:
- 子查询都放在小括号内;
- 子查询可以放在 from 后面、select 后面、where 后面、having 后面,但一般放在条件的右侧;
- 子查询优先于主查询执行,主查询使用了子查询的执行结果;
- 子查询根据查询结果的行数不同分为以下两类:
- 单行子查询(结果集只有一行),一般搭配单行操作符使用:
> < = <> >= <=
非法使用子查询的情况:子查询的结果为一组值、子查询的结果为空 - 多行子查询(结果集有多行),一般搭配多行操作符使用:
any、all、in、not in
一in 是属于子查询结果中的任意一个就行;any 和 all 往往可以用其他查询代替
- 单行子查询(结果集只有一行),一般搭配单行操作符使用:
⑧ 分页查询
应用场景:当要查询的条目数太多,一页显示不全
语法:
1 | select 字段|表达式,... |
特点:
- ① 起始条目索引从 0 开始,
起始索引=(查询页码-1)*每页显示记录数。 - ② 其实条目索引可以省略,如省略默认为0
- ③ limit 子句放在查询语句的最后;
- ④ 先执行 from,再执行 join on,接着 where,再接着 group by having,之后 select,然后 order by,最后limit。
示例:
1 | # 查询学生表中,分数位于前五的学生全部信息(假设前五名没有并列排名) |
⑨ 联合查询
union:合并、联合,将多次查询结果合并成一个结果集
语法:
1 | select 字段|常量|表达式|函数 【from 表】 【where 条件】 union 【all】 |
特点:
- ① 多条查询语句的查询的列数必须是一致的;
- ② 多条查询语句的查询的各列类型、顺序最好一致,各列数据类型也可以不一致,但必须兼容(可以隐含转换);
- ③ union 代表去重,union all 代表不去重。
示例:
1 | # (多个表):假设一班和二班均有一张成绩表,现在要把两张表的信息合并。 |
3. DML语言的学习【重点】
① 插入
在表中插入数据,有两种方式。
方式一(重点):
语法:
1
2insert into 表名(字段1,...)
values(值1,...);特点:
- ① 字段类型和值类型一致或兼容,而且一一对应;
- ② 字段的个数和顺序不一定与原始表中的字段个数和顺序一致,但必须保证值和字段一一对应;
- ③ 字段可以省略,默认为所有字段,并且顺序和表中的存储顺序一致;
- ④ 不可以为空的字段,必须插入值;
- ⑤ 假如表中有可以为null的字段,注意可以通过以下两种方式插入null值:字段和值都省略/字段写上,值使用null。
方式二:
1
2insert into 表名
set 字段1=值1,字段2=值2,...,字段n=值n;方式一优点:
方式一支持一次插入多行,语法如下:
1
2insert into 表名【(字段名,..)】
values(值,..),(值,...),...;方式一支持子查询,语法如下:
1
2insert into 表名
查询语句;
示例:
1
2
3
4
5
6
7# 在学生表中插入一条学生信息,学号:8,姓名:李四,班级:2,姓别:男,成绩:88,电话:123456789
# 方式一
insert into students(id,name,grade,gender,score,phone)
values(8,'李四',2,'男',88,'123456789');
# 方式2
insert into students
set id=8,name='李四',grade=2,gender='男',score=88,phone='123456789';
② 修改
**语法**:
1 | update 表名 |
**特点**:
如果没有where筛选条件,则会更改表中所有行。
示例:
1 | # 在学生表中修改李四的成绩为90分 |
③ 删除
删除表中数据,有两种方式。
方式一(重点):
delete语句**语法**:
1
2delete from 表名
【where 筛选条件】;**特点**:
- ① 如果没有 where 筛选条件,则会删除表中所有行;
- ② delect 删除的是表中的一行,而不是整个表,也不是一行中的某一个数据。
方式二:
truncate table语句语法:
1
truncate table 表名
特点:
- ① truncate table 不能删除某一行,而是删除表中所有数据;
- ② truncate table 语句删除效率更高,其实质是删除原来的表,然后重建了新表,而不是逐行删除表数据。
二者区别
- truncate table 不能加 where条件,而 delete 可以加 where 条件
- truncate table 删除带自增长的列的表后,如果再插入数据,数据从 1 开始,delete 删除带自增长列的表后,如果再插入数据,数据从上一次的断点处开始。
- truncate table 删除不能回滚,delete 删除可以回滚
示例:
1
2
3
4
5
6
7
8
9
10# 在学生表中删除李四的信息
# 只能用方式一,不能用方式二
delete from students
where name='李四';
# 删除学生表中全部信息
# 方式1
delete from students;
# 方式2
truncate table students;
4. DCL语言的学习【重点】
事务:一条或多条 sql 语句组成一个执行单位,这一组sql语句要么都执行,要么都不执行;
事务的特点:(ACID)
- 原子性(Atomicity):一个事务是一个不可分割的工作单位,其中的操作要么都做,要么都不做;如果事务中一个 sql 语句执行失败,那么已执行的语句也会回滚,数据库退回到事务前的状态,就像这个事务从来没有执行过一样,也就是说,对于一个事务而言,不可能只执行其中的一部分操作。
- 一致性(Consistency):事务执行结束后,数据库的完整性约束没有被破坏,事务执行的前后都是合法的数据状态。数据库总是从一个一致性的状态转换到另外一个一致性的状态。
- 隔离性(Isolation):数据库允许多事务并发对其数据进行读写和修改,一个事务的执行不受另外一个事务的干扰,通常来说,一个事务所做的修改在最终提交之前,对其他事务时不可见的(但是具体也要看隔离级别的设置状态)。
- 持久性(Durability ):事务一旦提交后,对数据的修改就是永久的,即便系统故障也不会丢失。
事务的使用步骤:
隐式事务:没有明显的开启和结束事务的标志,本身就是一条事务可以自动提交,比如 insert、update、delete
显示事务:具有明显的开启和结束事务的标志.
set autocommit=0;取消自动提交事务的功能,MySQL 默认采用自动提交模式,也就是说,如果不显示地开始开始一个事务,则每个查询都会被当作一个事务执行提交操作。
开启事务
start transaction;编写事务的一组逻辑操作单元(多条sql语句)
支持 insert、update、delete语句
【savepoint 回滚点名;】 // 设置回滚点,可以没有提交事务或回滚事务
commit;提交、rollback;回滚、rollback to 回滚点名;
事务的并发问题:
- 脏读:事务 A 访问数据时,读取到了事务 B 修改了但尚未提交的数据。(事务 B 没有提交,可能提交成功,但也有可能回滚)
- 不可重复读:事务 A 在访问数据时,由于事务 B 对数据进行了修改,使得事务 A 多次读取到的数据不一致。(违反了事务的一致性)
- 幻读:事务 A 读取某个范围内的数据时,事务 B 在该范围内进行了插入或删除,导致事务A再次读取该范围的记录时,会产生幻行。
如何避免事务的并发问题?(设置隔离级别)
| 隔离级别 | 脏读 | 不可重复读 | 幻读 |
|---|---|---|---|
| read uncommitted(读未提交) | 可能发生 | 可能发生 | 可能发生 |
| read committed(读已提交) | 不可能发生 | 可能发生 | 可能发生 |
| repeatable read(可重复读,默认) | 不可能发生 | 不可能发生 | 可能发生 |
| serializable(串行化) | 不可能发生 | 不可能发生 | 不可能发生 |
注意:事务隔离级别越高,性能越差。
设置隔离级别:
1 | set session|global transaction isolation level 隔离级别名; |
查看隔离级别:
1 | select @@tx_isolation; # mysql默认的隔离级别是repeatable read(可重复读) |